Delendum Research, Miden, Risc Zero
By Bobbin Threadbare, Dominik Schmid, Tim Carstens, Brian Retford, Daniel Lubarov, Andrei Nagornyi and Ventali Tan
Github repository: delendum-xyz/zk-benchmarking
Table of Content
Introduction
The purpose of this benchmarking project is to produce a collection of standard benchmarks for comparing the performance of different zero-knowledge proof libraries, in an easy-to-read format, including graphs and tables. The first question we ask ourselves is - who is the target audience?
Is it a) developers, who are not necessarily familiar with the internals of ZK systems, but are looking to make an informed decision based on the tradeoffs involved with using a given proving system for a concrete, real-world use case, or b) individuals who understand the broad underlying primitives and are interested in the performance of key cryptographic building blocks?
Our goal is to cover both1.
Principles
Relevant
Our benchmarks aim to measure the performance of realistic, relevant tasks and use cases. This allows third-party engineers to estimate how each proof system would perform in their application.
Neutral
We do not favor or disfavor any particular proof system. We seek to allow each proof system to show its best features in a variety of realistic test cases.
Idiomatic
We allow each proof system to interpret each benchmark in whatever way makes the most sense for that system. This allows each proof system to showcase their performance when being used idiomatically.
Reproducible
Our measurements are automated and reproducible.
What are we testing?
Performance
We measure proving time2 in various standard hardware environments, thereby allowing each proof system to showcase its real-world behavior when running on commonly available systems.
For each benchmark, we measure the performance of these tasks:
- Proof generating
- Verifying a valid proof
We start with smaller computations such as iterated hashing, merkle inclusion proof, and recursion, and will eventually move on to larger end-to-end scenarios.
The following graph explains our approach:
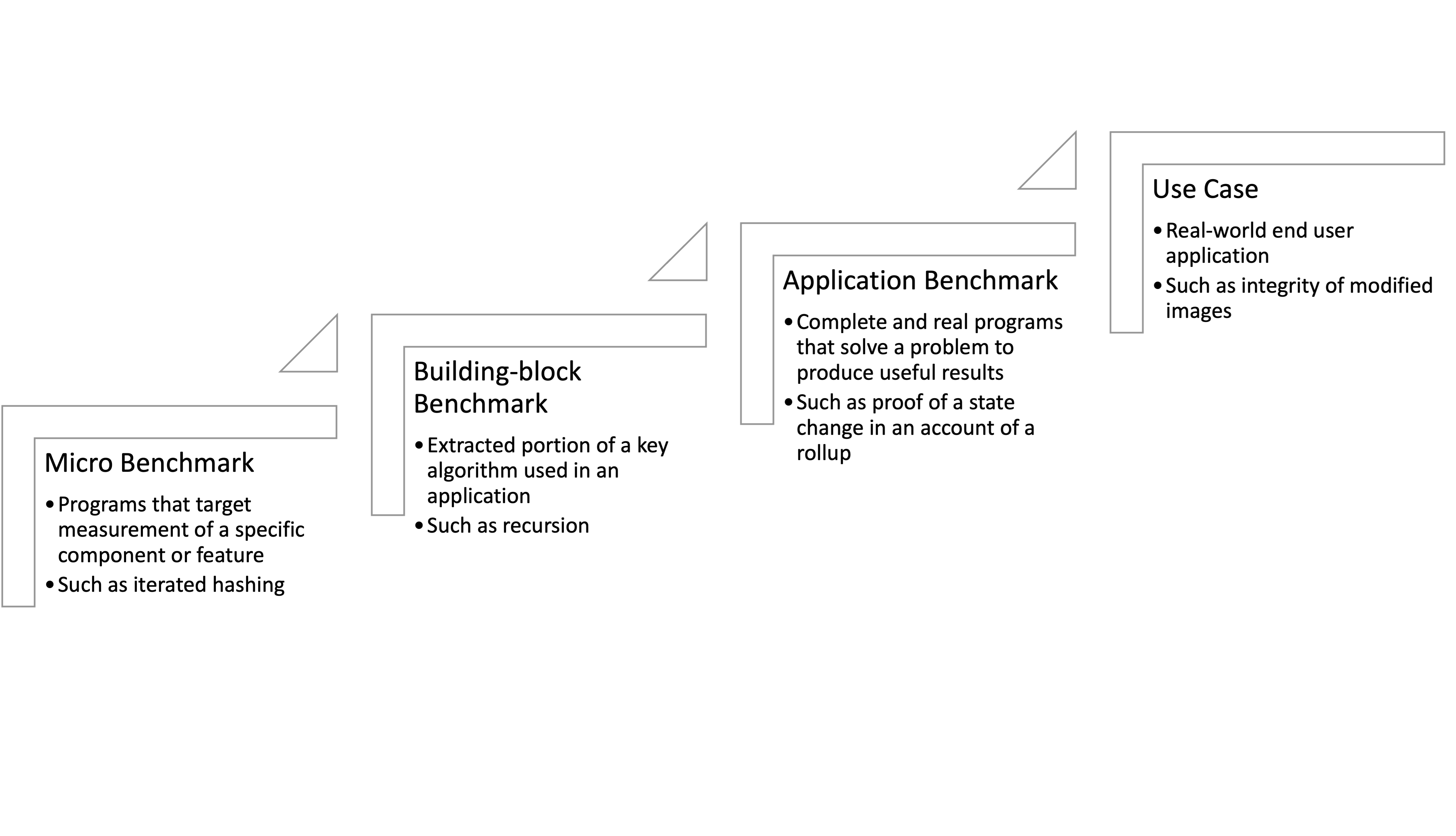
Definitions
Here are the definitions of the three tests mentioned above:
Iterated hashing
Iterated hashing is an essential building block for Merkle tree structures and whenever one needs to succinctly commit larger amounts of data.
To benchmark iterative hashing we compute a hash chain as H(H(H(...H(x)))), where H() is a cryptographic hash function, for some input x. As input x we chose a 32-bytes input [0_u8; 32] and the number of invocations of H() defines the length of the hash chain.
Merkle inclusion proof
A merkle inclusion proof proves that a certain leaf is part of a merkle tree. The VM is given the leaf and the merkle path and needs to prove inclusion by iterated hashing. We define the benchmark to pick a Merkle path of depth 32 and then the job_size is the number of Merkle paths we verify.
[Benchmarks will be presented soon]
Recursion
[Benchmarks will be presented soon]
Other factors
The following factors are also very important to consider and we will try to describe them in future:
Security
- What is the security model?
- How many “bits of security” does the system offer?
- Is it post-quantum?
- What hash functions does it support?
Ease of building new apps
- How hard is it to write new apps for the platform?
- Does it require custom circuits?
- Does it support custom circuits?
- Are there libraries and developer tools? How mature are they?
Upgradability
- Is the VM tightly coupled to its cryptographic core? Or is there an abstraction layer between them?
- If a new breakthrough in ZKPs took place tomorrow, would the VM be able to incorporate the new advances without breaking existing apps?
Sample results
Currently, the following ZK systems are benchmarked.
| System | ZKP System | Default Security Level |
|---|---|---|
| Polygon Miden | STARK | 96 bits |
| RISC Zero | STARK | 100 bits |
Prover performance
The table below shows the time it takes to generate a proof for a hash chain of a given length using a given hash function. This time includes the time needed to generate the witness for the computation. Time shown is in seconds.
| Prover time (sec) | SHA256 | BLAKE3 | RP64_256 | ||||
|---|---|---|---|---|---|---|---|
| 10 | 100 | 10 | 100 | 100 | 1000 | ||
| Apple M2 (4P + 4E cores), 8GB RAM | |||||||
| Miden VM | 1.91 | 40.39 | 0.96 | 9.87 | 0.05 | 0.28 | |
| RISC Zero | 1.29 | 5.48 | |||||
| AWS Graviton 3 (64 cores), 128 GB RAM | |||||||
| Miden VM | 0.49 | 3.99 | 0.33 | 2.06 | 0.05 | 0.13 | |
| RISC Zero | 0.40 | 1.59 | |||||
A few notes:
- For RISC Zero the native hash function is SHA256, while for Miden VM it is Rescue Prime.
- On Apple-based systems, RISC Zero prover can take advantage of GPU resources.
Verifier performance
The table below shows the time it takes to verify a proof of correctly computing a hash chain of a given length and a given hash function. Time shown is in milliseconds.
| Verifier time (ms) | SHA256 | BLAKE3 | RP64_256 | ||||
|---|---|---|---|---|---|---|---|
| 10 | 100 | 10 | 100 | 100 | 1000 | ||
| Apple M2 (4P + 4E cores), 8GB RAM | |||||||
| Miden VM | 2.42 | 3.73 | 2.56 | 2.52 | 2.28 | 2.42 | |
| RISC Zero | 1.92 | 2.44 | |||||
| AWS Graviton 3 (64 cores), 128 GB RAM | |||||||
| Miden VM | 3.26 | 3.54 | 3.24 | 3.47 | 2.81 | 3.04 | |
| RISC Zero | 3.03 | 4.05 | |||||
Proof size
The table below shows the size of a generated proof in kilobytes. Proof sizes do not depend on the platform used to generate proofs.
| Proof size (KB) | SHA256 | BLAKE3 | RP64_256 | |||
|---|---|---|---|---|---|---|
| 10 | 100 | 10 | 100 | 100 | 1000 | |
| Miden VM | 87.7 | 105.0 | 81.3 | 98.4 | 56.2 | 71.0 |
| RISC Zero | 183.4 | 205.1 | ||||
Roadmap
- Identify key performance metrics for evaluating the efficiency of zero-knowledge proof libraries (completed)
- Develop a set of test cases that exercise a range of different functionality in the libraries, including creating and verifying proofs for various types of statements (completed)
- Implement automation scripts for running the test cases and collecting performance data (completed)
- Set up continuous integration to regularly run the benchmarking suite and track performance over time (ongoing)
- Collaborate with other organizations to add more libraries, incorporate their test cases and use cases into the benchmarking suite (TODO)
- Publish the results of the benchmarking efforts in a public repository, along with documentation and scripts for reproducing the benchmarks (completed)
- Continuously update and improve the benchmarking suite as new features and functionality are added to the libraries (ongoing)
Call for collaboration
We are seeking collaborators to help us expand and improve our benchmarking efforts. If you are interested in joining us in this effort, there are several ways you can contribute:
- Help with adding benchmarks for additional proving systems.
- Suggest new benchmarks or test cases for us to include in our repository.
- Help us verify and validate the accuracy of the benchmarks and test cases that are already included in the repository.
- Contribute code or scripts to automate the running and reporting of the benchmarks.
- Help us improve the documentation and usability of the repository.
To get involved, please reach out to us via the repository’s issue tracker or email research@delendum.xyz. We welcome contributions from individuals and organizations of all experience levels and backgrounds. Together, we can create a comprehensive and reliable benchmarking resource for the ZK community.



